Vorteile einer Netzwerk-Überwachung (PRTG)
Unsere Hauptaufgabe als Ton-Verantwortlicher ist eigentlich der “gute Ton”. Wir wollen unseren Zuschauern das Bühnengeschehen akustisch ansprechend vermitteln. Je nach Situation kann dies von einem einfachen “die Sprache war gut verständlich” bis hin zu “die Musik hat mich gerührt/ergriffen/inspiriert” reichen.
Technik war seit jeher Mittel zum Zweck. Während Computer und Netzwerk-Technik anfangs gewisse Dinge vereinfacht haben, sind sie Stand heute teilweise elementarer Bestandteil einer Tonanlage. Viele Theater, die ich in den letzten Jahren betreut habe, basieren inzwischen auf AoIP, in den meisten Fällen Dante. Das bedeutet, dass nicht nur Steuer-Signale oder der File-Transfer über Switche läuft, sondern unser aller elementarstes Gut: das pure Audio-Signal.
Im Falle einer Netzwerk-Störung heißt mitunter: Stille. Und zwar nicht nur für den Tonmeister in seinem Studio oder den Musiker auf der Bühne. Stille betrifft ganz schnell den ganzen Saal. Eine Vorstellung muss ggf. unterbrochen oder ganz beendet werden.
Ich möchte dir heute meine Erfahrungen zum Thema Netzwerk-Überwachung präsentieren. Technische Defekte in einer Audio-Anlage treten über die Jahre immer wieder auf. Durch schnelle Erkennung und präzise Fehlerlokalisierung lassen sich diese aber bereits beheben, noch lange bevor sie sich durch einen Audio-Ausfall bemerkbar machen.
Typische Netzwerk-Probleme
Defekte Kabel-Verbindungen oder SFP-Module
Dies ist mit Abstand die häufigste Fehler-Ursache. Je nach Qualitätsstandard der Kabel und je nach täglicher Beanspruchung kommt es einfach vor, dass ein Stecker nicht mehr sauber funktioniert. Gleiches trifft auf SFP-Module zu. Günstige Produkte von Drittanbietern halten in der Regel nicht so lange wie die Originale von Cisco etc.
Ersatz kostet in der Regel nicht viel. Und meist hat man von allen Kabeln und Modulen ohnehin ein paar Exemplare im Regel liegen. Eine Fehlerbeseitigung lässt sich in der Regel schnell und unkompliziert durchführen - sobald man auf das Problem aufmerksam wird.
An vielen Stellen eines Switch-Netzwerks lassen sich Redundanzen vorsehen. Ein Ausfall eines Kabels bzw. SFP-Moduls wird nahtlos von einer redundanten Verbindung ausgeglichen, so dass die Veranstaltung nicht gefährdet ist. Umso wichtiger ist es allerdings, dass defekte Verbindungen zeitnah repariert werden. Andernfalls läuft das System nur noch auf der (womöglich letzten) Redundanz-Verbindung und jedes weitere Kabel-Problem führt dann tatsächlich zum hörbaren Ton-Ausfall.
Eine Netzwerk-Überwachung kann jeden einzelnen Port eines Switches einzeln überwachen. Im Fehlerfall kann anhand der Sensoren-Liste oder im Idealfall an einer übersichtlichen Map auf einen Blick abgelesen werden, welche Verbindung “down” ist.
Priorität für die Überwachung haben für mich immer die Uplink-Ports, d.h. die Verbindungen zwischen den Switchen. Diese sind in der Regel für den Tonmeister völlig transparent. Ein Ausfall macht sich hier erst bemerkbar, wenn es eigentlich schon zu spät ist.
Geräte ausgeschaltet / defekt
Ähnlich zur Überwachung der Uplink-Ports zwischen Switchen ist die Port-Überwachung der Geräte. Ein Ausfall macht sich in der Regel recht schnell bemerkbar, da ein Gerät beispielsweise kein Audio mehr liefert. Nichtsdestotrotz ist es hilfreich, die wichtigsten Geräte auch zu überwachen. Die Fehlermeldung passiert dann umgehend, und nicht erst, wenn das Gerät gebraucht wird. Außerdem hilft es der Übersichtlichkeit, wenn die gesamte Überwachung in einer einzigen Software zusammengefasst wird. Man sieht bei Dienstbeginn sofort jegliche potentiellen Probleme und muss nicht erst diverse Produkt-Software öffnen und durchsehen (wie Dante Controller, Amp Controller etc.).
Switch defekt
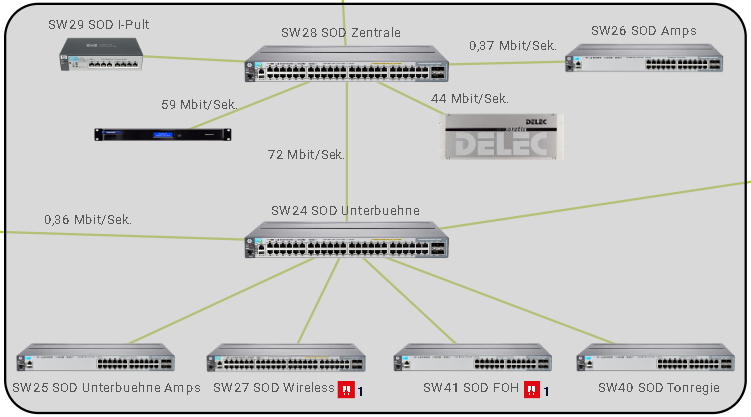
Ein Fehler, der äußerst selten auftritt, aber nichtsdestotrotz passieren kann: ein Switch ist komplett defekt. In solch einem Fall empfängt die Netzwerk-Überwachung keinerlei Informationen mehr von diesem Switch. Sämtliche Sensoren, die auf dem Switch angelegt wurden, werden somit als Fehler dargestellt.
Zu hoher Traffic
Jeder Netzwerk-Port an einem Switch hat eine maximale Datenrate, ebenso jedes Gerät. Am weitesten verbreitet sind aktuell 1Gb-Ports. 100Mbit-Ports sind in der Minderheit, aber sie kommen weiterhin auch bei Neugeräten vor. Viele Dante-Geräte mit nur 1-2 Kanälen nutzen beispielsweise den Ultimo-Chip von Audinate, der nur 100Mbit/s bietet.
Wenn sich der Traffic an einem Port seinem Limit nähert, kommt es recht schnell zu Problemen. Einige Daten-Pakete gehen verloren, so dass im Steuerungs-Bereich mitunter Verzögerungen auftreten. Im Audio-Bereich ist der Puffer sehr gering. Verlorene Pakete bedeuten in der Regel Audio-Aussetzer oder hörbare Verzerrungen. Es sollte deshalb immer ein Auge auf den aktuellen Traffic geworfen werden.
Jeder Switch bietet in der Regel die Möglichkeit, den Traffic für jeden Port auf seiner Web-Oberfläche anzuzeigen. Allerdings ist dies ein sehr aufwendiger Prozess, sich durch alle Switche und Ports zu klicken. Wesentlich komfortabler und zeitsparender ist das Anlegen von Sensoren für die wichtigsten Switch-Ports und nach Möglichkeit die Darstellung als Map.
Ein häufiges Szenario in Dante-Netzwerken ist zu hoher Multicast-Traffic. Dante-Geräte mit Ultimo-Chips werden schnell überlastet und schalten dann in der Regel auf Mute. IGMP-Snooping wäre eine Lösung, die es aber gewissenhaft in allen Switchen zu implementieren gilt. Etwaige Fehler (weiterhin hoher Traffic) lassen sich durch die Netzwerk-Überwachung sehr schnell lokalisieren.
Falsche Switch-Einstellungen
Spätestens, wenn man nicht nur einen sondern mehrere Switche betreibt, spielen Einstellungen in den Switchen eine entscheidende Rolle. Ein paar Beispiele für Einstellungen, die für alle Switche zu definieren bzw. aufeinander abzustimmen sind:
Spanning Tree (STP an/aus, welches Protokoll, bei MSTP: Name/Revision/VLAN-Mapping, Priorität pro Switch/Instanz)
IGMP Snooping (an/aus, welche VLANs)
IGMP Querier (welcher/alle Switche, welche VLANs)
QoS (an/aus, Modus, welche DSCP auf welche Queue)
SmartPort / AutoTrunk (an/aus)
EEE (an/aus)
Switchport-Mode (Trunk/Access)

Mit der Zeit kommt es vor, dass verschiedene Techniker Zugriff zu den Switchen bekommen und wissentlich oder unbeabsichtigt Dinge ändern. Im einfachsten Fall wird ein Switch gegen einen anderen ausgetauscht aufgrund eines Defekts oder weil ein größeres Modell mit mehr Ports benötigt wird. Nicht selten ist der Tausch schnell vorgenommen und die generellen Funktionen laufen wieder. Wenn elementare Einstellungen jedoch nicht gewissenhaft wiederhergestellt werden, kann dies schnell bedeuten, dass beispielsweise die Redundanz-Umschaltung nicht mehr funktioniert.
Wenn die Netzwerk-Überwachung gewisse Parameter überwacht, fällt jede Änderung sofort auf.
Topologie-Änderungen
Beim Netzwerk-Design hat man meist sehr genaue Vorstellungen, welche Route der Traffic zu nehmen hat, und welche Verbindungen als Havarie genutzt werden können. Letztlich will man sicherstellen, dass man zum einen optimale Performance in seinem Netzwerk erzielt (Latenz, Load-Balancing). Zum anderen will man aber auf jeden möglichen Defekt vorbereitet sein und installiert redundante Verbindungen und mitunder sogar Switche.
All dies kann jedoch zunichte gemacht werden, wenn unbemerkt fremde Switche hinzugefügt werden. Hat ein fremder (oder auch haus-eigener) Switch beispielsweise versehentlich eine höhere Priority-Einstellung für STP, so übernimmt dieser die Funktion der Root Bridge für das gesamte Netzwerk. Als Folge bauen sich alle Uplinks zwischen den Switchen neu auf und die zuvor gewollte Traffic-Gestaltung wird mitunter komplett zunichte gemacht.
Eine Überwachung der aktuellen Root Bridge (MAC-Adresse) an einigen Switchen informiert sofort, wenn nicht mehr der dafür vorgesehene Switch diese Aufgabe übernimmt. Dies kann im Falle von MSTP auch pro Instanz erfolgen (vorausgesetzt der Switch liefert diese Information per SNMP).
Dante-Subscriptions / niedriger Traffic
Ein Switch weiß zunächst natürlich nicht, welcher Traffic im Detail über einen Port fließen soll. Informationen wie sie im Dante Controller zu sehen sind, beispielsweise welche Subscription ein Empfänger bekommt, liefert der Switch nicht.
Nichtsdestotrotz lässt sich eine Netzwerk-Überwachung unterstützend auch für ein (statisches) Dante-Netzwerk nutzen. Geräte wie Verstärker oder Funk-Empfänger liefern meist eine sehr vorhersehbare Anzahl an Kanälen und somit konstante Datenrate. Für jeden Port an einem Switch ließe sich in der Überwachung sehr einfach ein unterer und oberer Schwellwert definieren.
Liefert ein Shure-ULX4D beispielsweise konstant rund 4Mbit/s, könnte ein unterer Schwellwert bei 2Mbit/s gesetzt werden. Wird dieser unterschritten, weil beispielsweise das Mischpult die Subscription nicht korrekt aufbauen kann, wird dies als Warnung angezeigt. Lange vor dem akustischen Soundcheck ist somit ersichtlich, wenn ein Empfänger netzwerktechnisch nicht korrekt eingebunden ist.

Ein oberer Schwellwert könnte etwa bei 10Mbit/s gesetzt werden. Dieser würde eine Warnung ausgeben bei zu hohem Traffic auf diesem Port, beispielsweise wenn unerwartet Multicast im Netzwerk auftritt.
Gleiches könnte auch für alle Dante-Verstärker vorgenommen werden, die in der Regel ebenfalls einen sehr konstanten Traffic bekommen.
Für Mischpulte und Stageboxen mit wechselnden Subscriptions variiert der Traffic. Eine Überwachung ist hier nur bedingt bzw. mit großem Schwellwert möglich.
Klimaanlage defekt, Lüftung verdeckt
Ein Bereich, der mit Audio zunächst nichts zu tun hat, ist die Temperatur-Überwachung. Viele Switche haben inzwischen einen Temperatur-Sensor eingebaut und lassen sich in der Regel per SNMP von einer externen Überwachung abrufen.
Selbst wenn man auf den ersten Blick nicht sieht, ob 45 Grad Celcius nun gut oder schlecht sind. Mit Hilfe einer Netzwerk-Überwachung, die ihre Werte beispielsweise einmal pro Minute abfragt und speichert, lässt sich daraus für jeden Switch ein Graph erstellen. Man erkennt zum einen sofort, wenn ein Switch generell höhere Temperaturen liefert als baugleiche Switche in anderen Räumen. Zum anderen sieht man anschaulich, wie sich die Temperatur ändert je nach Tageszeit. Switches in Amp-Racks oder in der Decke über dem Zuschauerraum schwanken durchaus um einige Grad, wenn die Amps eingeschaltet sind bzw. wenn der Zuschauerraum voll besetzt ist.
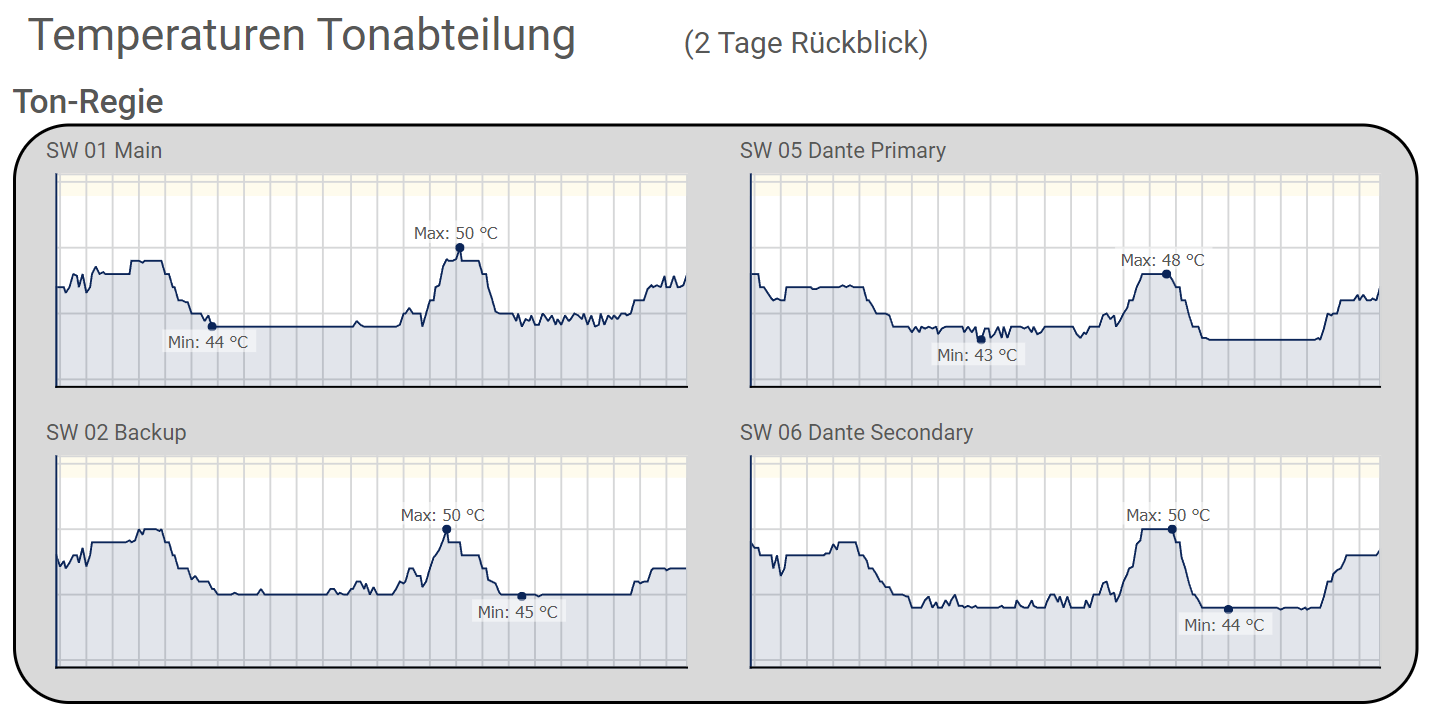
Die wichtigste Information der Graphen ist jedoch schnell zu erkennen, sobald sich die Temperatur oberhalb des üblichen Bereichs bewegt. Je schneller man jemanden zur Reparatur der Klimaanlage benachrichtigt, desto früher ist alles wieder im Normal-Bereich und je unwahrscheinlicher ist der Hitzetod eines Gerätes.
Selbst für Räumlichkeiten, die man täglich betritt, wie die Ton-Regie, hilft es, wenn man bereits am Morgen per Netzwerk-Überwachung sehen kann, dass die Klimaanlage ausgefallen ist. Bis zur Vorstellung am Abend lässt sich das Problem ggf. bereits beheben. Andernfalls bemerkt man den Defekt erst beim Betreten der Ton-Regie kurz vor dem Soundcheck und muss dann ggf. die Vorstellung in einer Sauna verbringen.
Die Überwachung der Temperatur und die schnelle Reaktion auf mögliche Defekte dient natürlich nicht nur der Langlebigkeit der Switche, sondern aller Geräte in diesem Raum.
Weitere Einsatzzwecke
Neben reinen Netzwerk-Geräten gibt es natürlich noch eine Vielzahl anderer Geräte, die ebenfalls per SNMP überwachbar ist.
Die Audio-Kreuzschiene Nexus aus dem Hause Stagetec liefert zu jeder ihrer Stageboxen neben der Temperatur auch noch weitere wichtige Informationen. Beispielsweise lässt sich die Anzahl der aktiven Netzteile abfragen. Sobald sich ein Netzteil verabschiedet, geht der Betrieb aufgrund genügend redundanter Netzteile nahtlos weiter. Aber letztlich muss man dies im Auge behalten und im Falle eines Defekts irgendwann mal eine Reparatur bzw. Austausch vornehmen.
Ein anderer Einsatzzweck wäre die Überwachung des freien Speicherplatzes auf einem NAS, um rechtzeitig mitzubekommen, wenn der Platz knapp wird und man ggf. weitere Festplatten bestellen muss.
Wege der Benachrichtigung
Die beste Überwachung nützt natürlich nichts, wenn das Team vor Ort nichts von den Fehlern erfährt. Glücklicherweise gibt es einfache Wege, den Status nicht nur einzusehen, sondern sich sogar benachrichtigen zu lassen. Ich habe mir in den letzten Jahren verschiedene Netzwerk-Überwachungen angeschaut und arbeite inzwischen ausschließlich mit PRTG Network Monitoring. Insofern beziehe ich mich im folgenden auf die Funktionen dieser einen Software.
Sensor-Liste
Die Hierarchie in PRTG besteht im wesentlichen aus Gruppen (beispielsweise pro Bühne oder Raum), dann aus physischen Geräten (mit jeweils einer IP-Adresse), und letztlich aus mehreren Sensoren pro Gerät.
Die entsprechende Geräte-Liste dienst nicht nur dem Anlegen der Geräte und Sensoren, sondern liefert gleichzeitig auch eine schnelle Status-Rückmeldung.
Sensoren, deren Werte innerhalb der eingegebenen Schwellwerte liegen, sind mit einem grünen Haken versehen. Jeder Sensor hat dazu noch zwei obere und untere Schwellwerte. Wird dieser unter- bzw. überschritten, liefert der Sensor eine Warnung (gelb) oder Fehlermeldung (rot).
Im einfachsten Fall belässt man seine Netzwerk-Überwachung bei dieser Liste und hat bereits alle Informationen verfügbar.
Map
Etwas eleganter und vor allem verständlicher ist die Erstellung einer Map, also einer Übersichtskarte. Diese bietet eigentlich keine neuen Informationen, aber sie bietet durch die grafische Aufbereitung eine bessere Darstellung der Topologie. Es lassen sich beliebig viele Maps in PRTG anlegen, so dass für unterschiedliche Mitarbeiter bzw. Fach-Abteilungen ggf. unterschiedliche Grade an Details gezeigt werden können. Oder es lässt sich neben einer Gesamt-Übersicht aller Switche eine Detail-Map pro Bühne erstellen mit den einzelnen Geräten.
Durch Links lässt sich einfach zwischen den Maps hin- und her navigieren, um beispielsweise schnell eine separate Seite für die Temperatur-Graphen erreichen zu können.
Und jede Map kann bei Bedarf öffentlich freigegeben werden, so dass sie auch ohne PRTG-Login über einen Webbrowser einsehbar ist. Ich hinterlasse in der Regel auf allen PCs in einem Theater ein Lesezeichen im Browser zur PRTG-Übersichtsseite, damit jeder Kollege bei Bedarf sehen kann, ob mit dem Netzwerk alles in Ordnung ist, oder ob ggf. an irgendeiner Stelle Handlungsbedarf besteht.
Benachrichtigung
Und wer nicht ständig die Netzwerk-Seite in seinem Browser geöffnet haben will, aber dennoch jeden Fehler mitbekommen will, der kann sich von PRTG per Email benachrichtigen lassen. Es lassen sich Regeln erstellen, welche Art von Fehler für welchen User/Email gemeldet werden soll. Für Netzwerke, die nur eine Abteilung (z.B. die Ton-Abteilung) betreffen, reicht es völlig aus, jegliche Fehler an den Abteilungs-Admin zu schicken oder ggf. an die ganze Abteilung. Im Normalbetrieb sollte hier kaum etwas geschickt werden. Und falls tatsächlich mal ein Uplink-Port ausfällt, kann es nicht schaden, wenn es alle mitbekommen.
Letztlich sei noch die PRTG-App erwähnt, die ebenfalls im Fehlerfall benachrichtigen kann und auch Einblick in die Geräte-Liste und Maps bietet. Um dies auch außerhalb des Theater-WLANs nutzen zu können, muss der PRTG-Server allerdings öffentlich erreichbar sein.
Kosten und Aufwand
Die gute Nachricht vorweg: Es gibt PRTG Network Monitoring als Freeware mit 100 Sensoren kostenlos (Download-Link). Und diese Version kann nach Bedarf später jederzeit in eine lizensierte Version umgewandelt werden.
Die kleinste Version nach der Freeware ist die Version mit 500 Sensoren für USD 1899,-. Ich bin lediglich Nutzer bzw. externer Inbetriebnehmer ohne jegliche Verbindung zu PRTG. Insofern verweise ich für die Details und Beschaffung auf Paessler PRTG.
PRTG läuft auf einem Standard-PC, der in jedem Theater mehrfach vorhanden sein dürfte. Der PC muss Zugriff auf alle Switche haben. Alle Sensoren werden etwa einmal pro Minute abgefragt. Selbst bei 500 Sensoren stellt dies keine große Belastung an die CPU oder das Netzwerk dar. Ich würde trotzdem empfehlen, den PRTG-Server auf einem reinen “Steuer-PC” laufen zu lassen, nicht auf einem PC mit vorstellungsrelevanten Audio-Zuspielungen oder -Aufnahmen. Es empfiehlt sich zudem, den PC dauerhaft laufen zu lassen.
Die Grundeinrichtung von PRTG für ein typisches Netzwerk mit 10-15 Switchen, d.h. das Anlegen der Devices und Sensoren, sollte sich innerhalb eines Tages erledigen lassen. Voraussetzung hierfür ist natürlich, dass das Netzwerk selbst bereits solide konfiguriert ist. Die Netzwerk-Überwachung selbst optimiert das Netzwerk nicht, es zeigt lediglich den Status der Switche und Ports an.
Sensoren wie Ping oder Port-Traffic sind ohne große Vorkenntnisse einzurichten. Für hersteller-spezifische Sensoren wie Temperatur, Spanning-Tree, IGMP etc. werden jedoch die exakten OIDs für den jeweiligen Parameter benötigt. Diese zu recherchieren kann schnell etliche Stunden in Anspruch nehmen, insbesondere ohne Erfahrung mit SNMP.
Das Erstellen einer grafisch anschaulichen Map dauert meist länger als das Anlegen der Sensoren selbst. Für eine gute Übersicht (auch für neue Mitarbeiter bzw. Freelancer) empfiehlt es sich, für die wichtigsten Geräte Fotos anzufertigen bzw. runterzuladen und in PRTG einzubinden. Wenn man weiß, was man tut, würde ich den Gesamt-Aufwand auf etwa 3 Tage schätzen.
Fazit
Die Kurzfassung: egal, ob ich ein Netzwerk neu einrichte oder ein bestehendes optimiere - PRTG installiere ich eigentlich immer. Und die 100 Versionen der Free-Version reichen für kleine Netzwerke mit rund 10 Switchen locker aus. Damit lassen sich nicht nur die Uplinks überwachen, sondern auch einige Grund-Parameter jedes Switches und die wichtigsten Geräte.
Sobald das Netzwerk vorstellungsrelevant wird - und das sehe ich inzwischen an den meisten Theatern und Opernhäusern - ist es fast schon fahrlässig, sein Netzwerk nicht täglich im Auge zu behalten. Genauso wie man einen Soundcheck macht, um seine Mikrofone und Lautsprecher zu prüfen, so sollte auch ein Check des Netzwerks zur täglichen Routine gehören.
Wenn sie erstmal eingerichtet ist, übernimmt die Netzwerk-Überwachung diese wichtige Aufgabe ganz nebenbei. Mit einem einzigen Blick auf eine (hoffentlich hübsche) Übersichts-Map lässt sich der Status aller Switche und Geräte ablesen. Etwaige Probleme werden sehr viel früher erkannt und präzise angezeigt, als wenn man sich mit seinem Netzwerk erst beim Ton-Ausfall beschäftigt.
Und wenn man erstmal eine Übersichts-Seite des aktuellen Status-Quo hat, stellt man meistens fest, welche Fehler im Netzwerk bislang noch bestehen bzw. welche Verbesserungen man noch einarbeiten kann.
Der Vorteil einer zentralen Überwachung besteht zudem darin, dass man nicht die jeweilige Spezial-Software seiner Geräte öffnen muss. Vielmehr sammelt eine Netzwerk-Überwachung Hersteller- und ggf. Abteilungs-übergreifend den Status aller Geräte. Ein Abteilungsleiter oder der für die technische Instandhaltung verantwortliche Mitarbeiter kann von seinem Büro aus Probleme erkennen und ggf. reagieren, auch während die Probe oder Vorstellung läuft und ohne, dass er für diesen Statusbericht Zugriff aufs Mischpult-System bräuchte.
Ich möchte diesen “stillen Mitarbeiter” nicht mehr missen und kann ihn wärmstens für jede Fest-Installation empfehlen.
Gerne helfe ich natürlich beim Aufsetzen der Überwachung bzw. bei der Netzwerk-Konzeption insgesamt.
Weitere Blog-Artikel zum Thema Netzwerk und Dante: